Python is an interpreted, high-level,
general-purpose programming language used for many different types of
applications within the development community and MongoDB is a NoSQL database
which has become pretty popular throughout the industry in recent years. NoSQL
databases provide features of retrieval and storage of data in a much different
way than their relational database counterparts.
In this blog I have share some basic examples, commands, Software used in process of interaction between MongoDB and Python,
Why You Should Use MongoDB?
The following are some of the MongoDB advantages:
- Flexible schema – it maintains a hierarchical data structure
- A large number of the MongoDB drivers and client libraries. MongoDB Drivers are used for connecting client applications and the database. For example, if we have a Python program and we want to connect it to MongoDB, we need to download and integrate the Python driver so that the program can work with the MongoDB database
- Flexible deployment
- The document-oriented storage (in the form of JSON style documents)
- JavaScript as a language for querying
- Dynamic querie
- Index support
- Profiling queries
- Effective storing of large amounts of binary data, such as images and videos
- Journaling operations of modifying data in the database
- Supporting fault tolerance and scalability: an asynchronous replication, a replica set and a distributed database connected to the nodes
- Can work in accordance with the MapReduce paradigm. MapReduce – a programming distributed computing model provided by Google that is used for parallel computing on a large, multiple petabytes, data sets in the computer clusters
- Full-text search, supporting Russian language and morphological analysis
- MongoDB supports horizontal scalability through sharding. Sharding is the process of storing data records across multiple machines. This approach is used in MongoDB to meet the data growth demands. As the size of the data increases, a single machine may not be sufficient to store the data nor provide an acceptable read and write throughput. Sharding solves the problem with horizontal scaling.
For decades, SQL databases used to be one of
the only choices for developers looking to build large, scalable systems.
However, the ever-increasing need for the ability to store complex data
structures led to the birth of NoSQL databases, which allow a developer to
store heterogeneous and structure-less data.
PyMongo
The official driver published by the Mongo
developers is called PyMongo. This is a good place to start when first firing
Python up with MongoDB. The first thing you’ll want to do is to install PyMongo
in your environment which is done using PIP3

When you will run above command in shell it
will load pymongo files in your environment. Once you are done with the setup, start your Python console and run the
following command:
import pymongo
If it runs without raising any exception
within the Python shell then your install worked just fine. If not, then
carefully perform the steps again.
Create
Database & Establishing a Connection
To create a database in MongoDB, start by
creating a MongoClient object, then specify a connection URL with the correct IP
address and the name of the database you want to create. MongoDB will create
the database if it does not exist, and make a connection to it.
You can check
if a database exist by listing all databases in your system:
Why it
doesn’t have testDB which we just created? As you know MongoDB waits until you
have created a collection (table), with at least one document (record) before
it actually creates the database (and collection). So let’s create a collection called "customers"
and insert a record, or document into this collection

As you see created a dictionary object with name and address and inserted into collection “customers”. If it runs without raising any exception then it worked fine but to verify we can always print inserted id of document. Or you can use Robo Mongo to check if collection created with document or not, at my end after these commands execution Robo Mongo looks as follows

You can insert multiple documents using insert_many method
You can find all documents in Robo Mongo or run find command, when view documents in Robo Mongo it will look as follows

With find
command in script using IDLE (Python 3.7 64-bit)

Output of
script will be listing all documents of collection

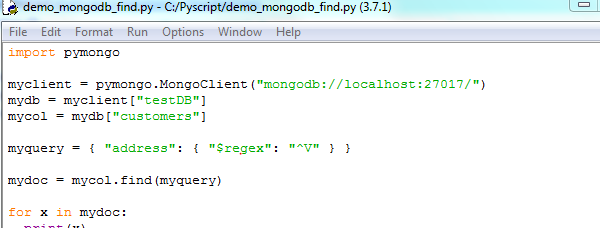
Find
document(s) with the address Vancouver

Find documents where the address starts with the letter "V":
Update
Collection
You can
update a record, or document by using the update_one() or update_many() method.

Delete
Document
Delete the
document with the address “Vancouver" using delete_one or delete_many

I have covered all crud operations using PyMongo and core is the MongoClient object. For more examples & method details you can refer Documentation at location https://api.mongodb.com/python/current/
MongoEngine
MongoEngine is Object-Document
Mapper (ORM-like, but for document-oriented database) that allows to work with MongoDB
on Python. To specify the schema document, we create a class that is inherited
from the Document base class. Fields are determined from adding the document’s
class attributes. You can install MongoEngine again using PIP as shown below

for demo purpose
only I will create very common example class which is very basic script that’s
will connect to mongo DB, Define document and document's schema of WikiPage
with just title & description

If I open
Robo Mongo I will see page1 & page 2 entered into wiki pages

For more examples &
method details you can refer Documentation at location http://docs.mongoengine.org/ As Agreed
Today I focused on Python & MongoDB interaction, next time I will share
examples on Object-Oriented Programming in Python.
What do you
think? Let me know your inputs & suggestions.
Courtesy: Several online blogs, you tube videos, tutorials & other
resources