Recently I used DynaTrace, it’s a leading application performance management tool and
is being widely used.It comes with advanced features for
monitoring Java and .NET applications, which aids to identify bottlenecks or
errors in the application easily. Pure Path technology used in DynaTrace
provides end-to-end transaction level details; from browser, across all tiers and database. It
helps to uncover performance issues even at the code level and also details of
transactions invoking external services. This tool detects
abnormalities in response time, transaction rate, through put and system
usage
Magic of Pure Path:
A Pure Path is the horizontal view of a transaction in a
monitored application environment and is the basis for top down analysis, which
is defined by analyzing how an application or transaction is impacted by the
underlying infrastructure.
Typically, a Pure Path is composed of data sent
asynchronously by many different Dynatrace Agents, which then send the data to
the Dynatrace Collector. The Collector buffers and enriches the data and passes
it on to the Dynatrace Server, which is responsible for Pure Path construction,
analysis, and offline storage. Pure Paths provide the superset of data for
creating specific Business Transactions and high-level Measures
Once your Collector is configured, Agent is in place and Dynatrace
Client is installed, In Navigation pane there will be options for Diagone
Performance & Diagnose Runtime, these two are used for Pure Path analysis
and Memory leak analysis…

Pure Path:
Go to Diagnose Performance à Pure Path menu
item when double click on Pure path dash-let it opens dashboard, with option of
filtering on last 5 minutes, 30 minutes, 1 day etc. With filter option last
five minutes up, you need to visit your
application page then Dynatarce agent is going to capture every single request
made to worker process and display result in very neat and clean tabular format
as shown below
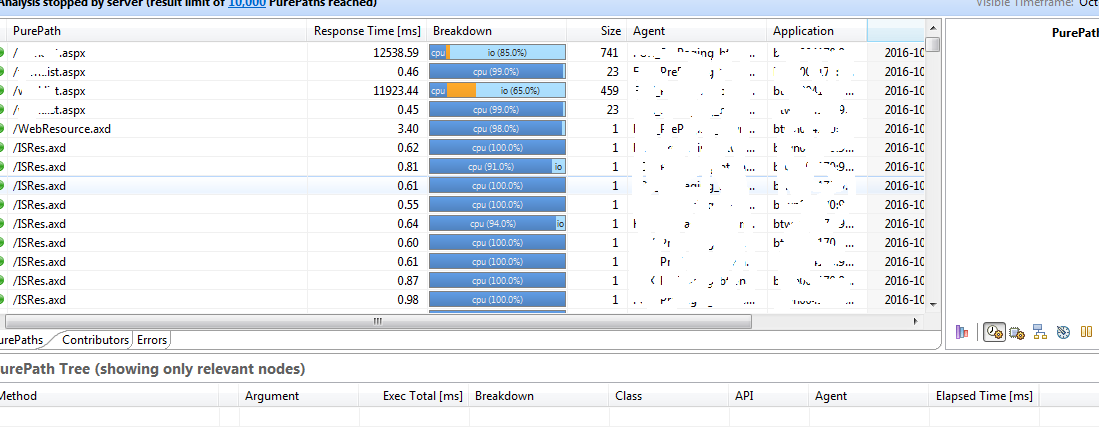
I have removed page name & server details but you can see
its very simple table displaying response time for page, suspension time, GC
Size etc .. When right click on any request you get option to see detailed
drill down of request.. Dynatarce client capture request from every single
request to the very end of response

You only need to scroll up
and down. You can always right click on each element to have more
contextual information like on which server it was running on. In our
case we added the IP address of the remote user and its username. By
default it’s showing you only the relevant nodes (method calls where most of
the time was spent) but you can chose to see all of them.
Check out the YouTube
Tutorial they have on “PurePath Deep
Dive” if you want to learn more about it.
Here I tried to cover basic steps for pure path analysis, in
next blog of this series I will capture steps to analyze memory leak for
identification of classes and objects causing memory leaks.
Courtesy: Several online blogs & other resources https://www.dynatrace.com/community/blogs/
